What is deferred compilation?
When I talked about row estimations for table variables, I mentioned ‘deferred compile’, but didn’t give a whole lot of details. What, then, is a deferred compilation? Let’s start with how batches work normally.
T-SQL is an interpreted language. While we talk about compiles, they’re not compilations in the sense of what happens to C++. There’s no conversion of the script to a machine language or intermediate language which is used from that point onwards. Every time a batch executes, it has to be parsed, bound and have an execution plan generated or fetched from cache.
When a batch is parsed, the entire batch is parsed.
SET STATISTICS TIME ON
GO
SELECT * FROM dbo.Clients
SELECT * FROM dbo.StarSystems ss
INNER JOIN dbo.Stations s ON s.StarSystemID = ss.StarSystemID
SELECT GETDATE()
GO
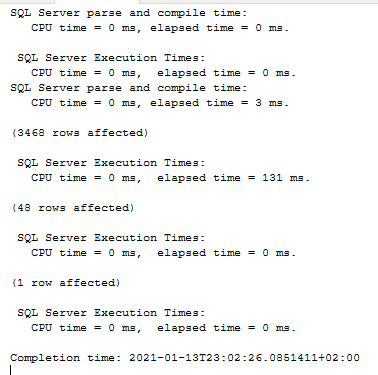
Ignoring the SET STATISTICS, we’ve got there one batch with two queries in it. Two queries, two execution times but only one parse and compile time. The entire batch was compiled and then the batch was executed.
If we set up an XE session to track compiles, it shows similar
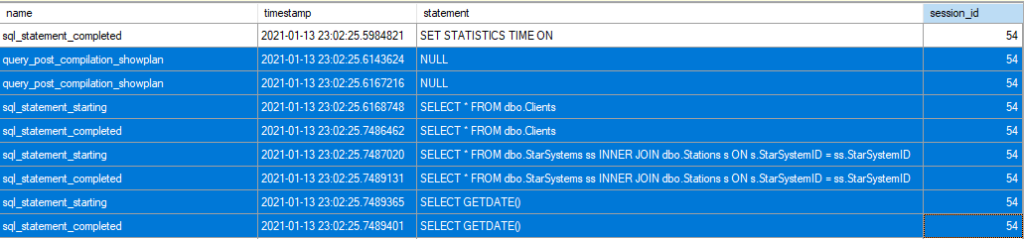
The XE session shows that the compilations for both queries were completed before either started execution.
But what happens if we reference a table that doesn’t exist?
SET STATISTICS TIME ON
GO
SELECT * FROM dbo.Clients
SELECT * FROM dbo.StarSystems_DoesNotExist ss
INNER JOIN dbo.Stations s ON s.StarSystemID = ss.StarSystemID
SELECT GETDATE()
GO

The first of the queries is still compiled, but not the second. The second can’t be compiled because it references an object that doesn’t exist. The first query then executes, and right before when the second query would execute, it’s sent back to be bound and optimised. In this case, the object still doesn’t exist and so we get an error.
Msg 208, Level 16, State 1, Line 6.
Invalid object name 'dbo.StarSystems_DoesNotExist'
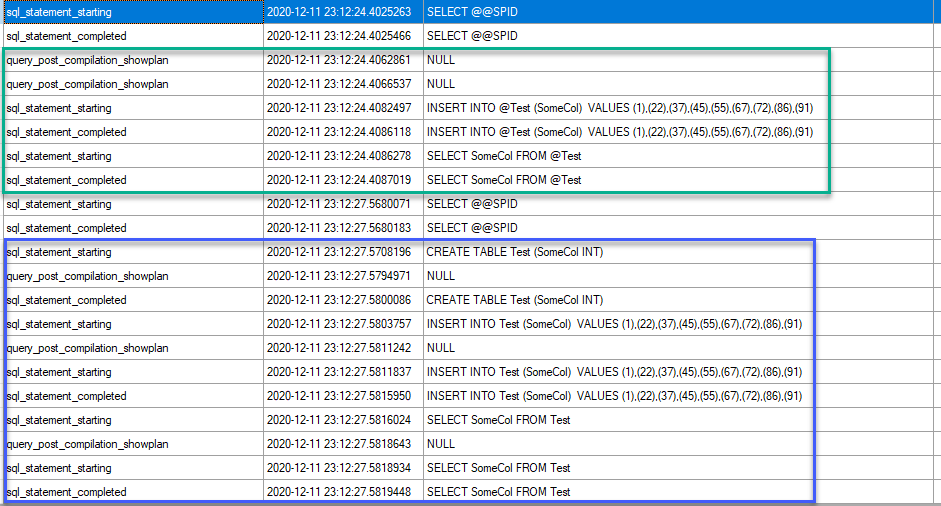
But if the object was created between the start of the batch and the query that uses it, we get a still different result
SET STATISTICS TIME ON
GO
SELECT * FROM dbo.Clients
SELECT * INTO #StarSystems FROM dbo.StarSystems
SELECT * FROM #StarSystems ss
INNER JOIN dbo.Stations s ON s.StarSystemID = ss.StarSystemID
SELECT GETDATE()
GO
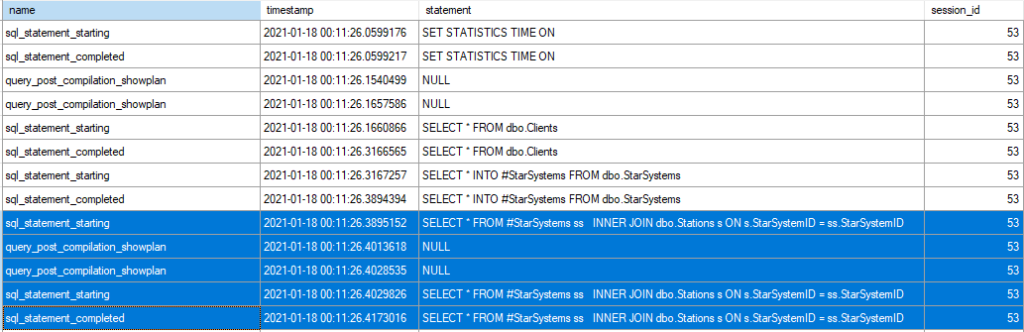
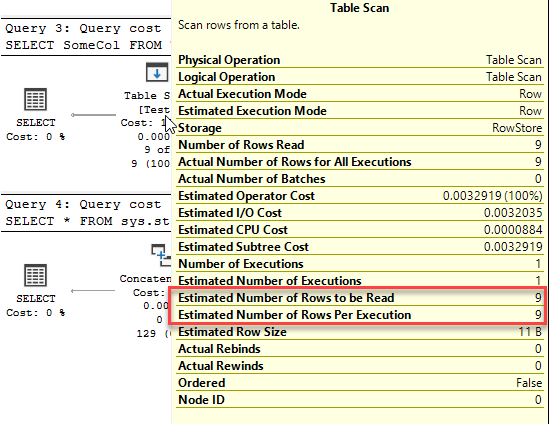
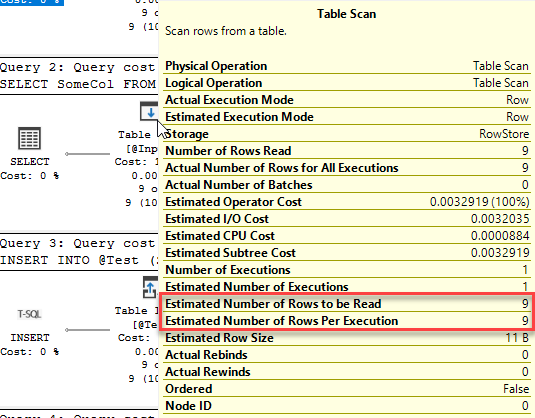
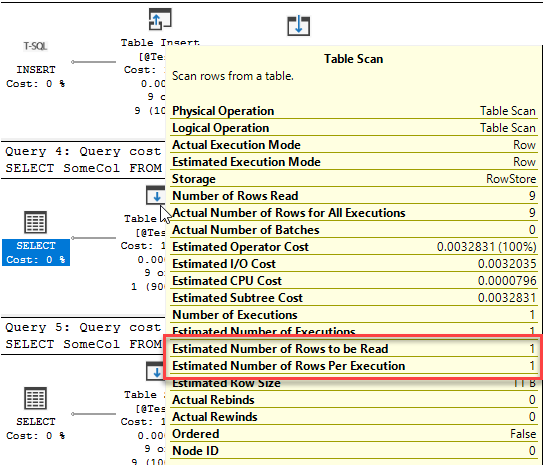
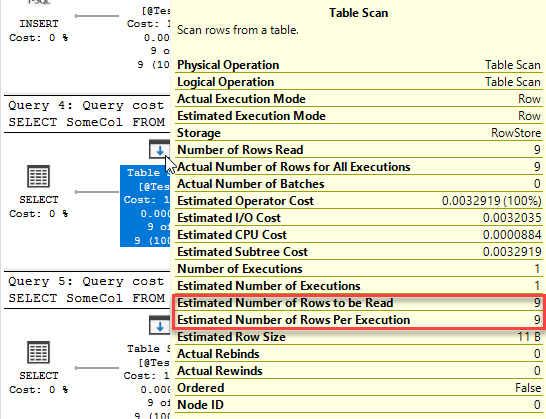
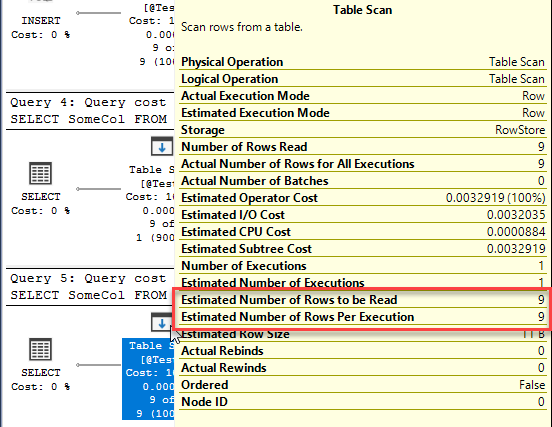
This time we have three queries. Two of them get an execution plan generated when the batch starts, but the third can’t, because the table it references doesn’t exist. Instead, the statement starts executing but can’t execute because there’s no plan. It gets sent back to the optimiser to be compiled, then the query executes.
This is a deferred compile (also called deferred resolution). A compile that does not happen when the batch starts, but is rather deferred until the point that the query itself executes, usually because the table does not exist at the point the batch starts..
























![TopProperties[3]](https://www.sqlinthewild.co.za/wp-content/uploads/2016/03/TopProperties3.png "TopProperties[3]")



