Given that SQL Server 2016 is coming ‘real soon now’, it’s probably well past time that I write up some thoughts on new features.
The first one I want to look at is a feature that I’m so looking forward to getting to use, the Query Store.
Query Store is essentially a flight recorder for a SQL database. It tracks queries, their execution characteristics and their execution plans. The best part is that this information is persisted into the database and hence is not lost on restart, as the current performance-related DMV contents are.
The data is aggregated over a defined period of time, by default an hour. This will probably be fine for most cases, if there are performance problems that come and go in fractions of an hour (like a case I had last year), then that interval may need to be reduced, depending on the type of problem.
There are lots and lots of blog posts on how to enable it and how to query it and the like, so I’m not going to repeat that info here. See http://sqlperformance.com/2015/02/sql-plan/the-sql-server-query-store for all of that kind of info.
There’s two main aspects that I want to discuss about this feature. Let’s start with a screenshot of one of the Query Store’s built-in reports, the top resource-consuming queries.
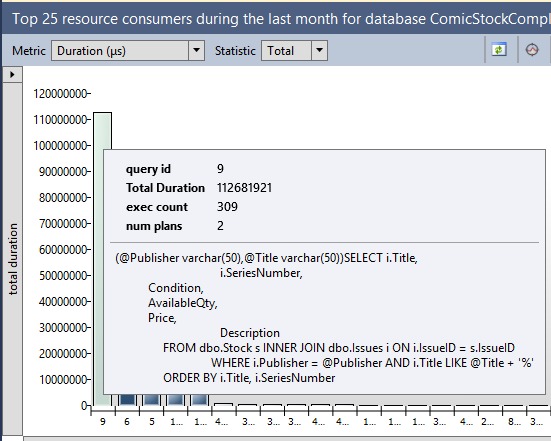
The longest-running (on aggregate) query in this database is this nice parameterised query against the Stock and Issues tables. In the pane at the bottom of that report I can see its query plans.
Nothing really fancy there, except for one thing.
The server that I pulled those reports from has never had that query run against it. I pulled that report from an Azure VM that I set up last week. The workload all dates from 3 weeks ago.
Query Store data is persisted into the database, which means it’s included in a backup. I ran the workload against one server, backed up the database, restored it elsewhere and then queried the query store data. And there’s an even better part.

Before running those Query Store reports, I dropped every table in the database.
Before this, to get the aggregated performance characteristics of a workload, I’d have to run a server-side trace or an extended events session, write the results out to a file, copy the file to my analysis server, load them into a table and aggregate the results. It’s a process that could take a day or two.
Now (or at least once SQL 2016 becomes widespread) I can just ask the client for their latest backup as all the query performance data I want is in there. If they’re uncomfortable with me having access to the data, they can restore the DB somewhere, drop all the tables then back up the ‘empty’ database and send me that. Much faster, and far fewer worries about having potentially missed something that ran at a time the trace wasn’t running.
The second thing isn’t so much about Query Store, as it is about the message that’s coming from Microsoft about it. Over and over and over they keep talking about how Query Store can be used to force a good query plan. It’s not hard to do.
Let’s take an example of a query with a parameter sniffing problem.
CREATE PROCEDURE GetOrders (@StartDate DATETIME) AS SELECT OrderDate, IssueID, QtyOrdered, Total FROM Orders WHERE OrderDate > @StartDate; GO
The index on OrderDate isn’t covering, so a seek and key lookup is optimal for small numbers of rows and a clustered index scan is better for large numbers of rows
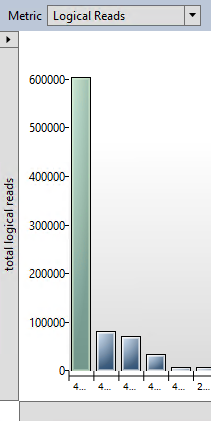
The query in question is by far the worst query in terms of logical reads on the server.

And it has two plans associated with it. The one at the top (plan 453) is the seek and key lookup. The one at the bottom (plan 452) is the clustered index scan.
Select the desired plan. It appears in the bottom section, then
![]()
And problem solved.
Well…
I’d argue that’s less fixing the problem than hiding it. Sure, you won’t get a different plan, or at least that’s the idea. (While testing I did manage to get a different plan to the forced one, I need to investigate further why.) But is that forced plan the best solution? In this example, widening the index would have been a better solution. In other cases you might rather want to split the procedure into two, one for some date values one for others, or add the recompile hint, or even change the query.
Forcing a plan is great for stopping a problem that’s currently bringing production down, but it’s far from the only thing that will ever be done now. For starters forcing a good plan requires that there is a good plan, and if the query is written so it can’t use indexes or there are no suitable indexes, there won’t be a good plan to force. It’s a nice tool, but that’s all it is, another tool in the performance tuning box. It’s not a replacement for all other tuning work that’s ever been done
Now, I wonder how long it’s going to take to get my clients to upgrade.