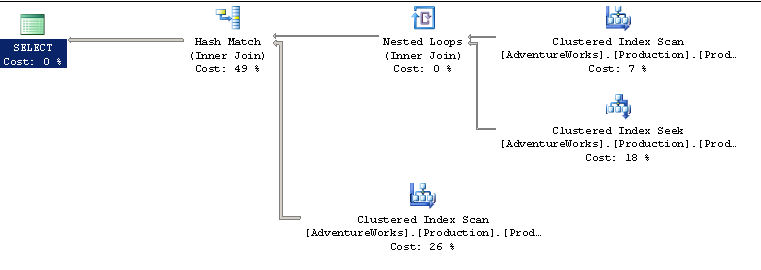
Execution plans from Profiler
There is another way to get hold of query execution plans than through query analyser/management studio. In SQL 2005, Profiler has a large number of plan-related events. It had some in SQL 2000, but they were quite hard to work with.
The interesting ones in SQL 2005 are as follows, all found under the performance collection in profiler.
- Showplan XML
- Showplan XML for query compile
- Showplan XML Statistics Profile
As soon as one of these is selected, a third tab appears on the trace setup screen, asking for the file to save the xml plans. You can choose to save the plans within the profiler trace file, however the file tends to get very, very large when that is done.
The Showplan XML for query compile event fires every time a query is compiled, and it produces an estimated execution plan.
The showplan XML event fires every time a query runs, and it produces an estimated execution plan. When I tested it, it looked as though it was the actual plan, however all the run-time information (actual rows affected, etc) were 0
The Showplan XML statistics profile event fires every time a query runs and produces an actual query plan, with the run-time information in it.
Be careful when running profiler with these events on a busy system as they are quite large, and you can end up with very large output files very quickly. Also, on a busy server they can be very frequent events and capturing them with the profiler front end could result in performance degradation.